1. SPSS 데이타의 편집
입력이 완료된 이후의 데이타라도 데이타 편집기를 활용하여 얼마든지 추후에 이를 수정할 수 있으며, 필요할 경우 다양한 편집 활동을 할 수 있습니다.
즉,
- 입력된 변수 값의 삭제나 수정이 가능합니다. 마이크로소프트 엑셀과 같이 직접 커서를 움직여서 새로운 값을 기존 값 위에 입력하거나, 기존 값을 삭제 후 재입력할 수 있습니다.
- 변수 값을 복사하여 옮겨붙이기도 가능합니다. 하나의 셀이나 여러개의 셀, 혹은 행이나 열 단위의 데이타를 삭제하거나 다른 곳에 복사할 수 있습니다.
이처럼 데이타를 편집하기 위해서는 다음과 같은 절차가 필요합니다.
1) 삭제하거나 복사하고 싶은 셀들을 지정합니다. 마우스 오른쪽 버튼을 누르면 한 개의 셀을 지정할 수 있고, 쉬프트키를 누른상태에서 마우스를 누르면 여러개의 셀을 한번에 지정할 수 있습니다.
2) 마우스 오른쪽 버튼을 누르거나 메뉴의 편집(E)에서 잘라내기(T)나 복사(C)를 선택합니다. 잘라내기는 원래 셀로부터 다른 셀로 데이타를 이동함을 의미하며, 복사는 똑같은 셀의 내용은 다른 셀에 하나 더 만드는 것을 의미합니다.
3) 복사해 붙이기 원하는 셀의 위치에 마우스 커서를 옮깁니다.
4) 마우스 오른쪽 버튼 혹은 메뉴의 편집(E)에서 붙여넣기(P)를 선택합니다.
2. 행과 열의 추가 및 삭제
기존의 파일에 새로운 케이스를 추가하거나 삭제할 수 있습니다. 이를 설명하기 위해서 5차시에서 사용하였던 간단한 설문 문항과 데이타를 다시 보도록 하겠습니다.
|
문항 1. 당신이 좋아하는 과목은 다음중 무엇입니까? 1) 수학 2) 과학 3) 영어 4) 기타 문항 2. 당신의 평균 기말고사 점수는 몇 점입니까? 직접 입력하여 주시기 바랍니다. ________ 점 문항 3. 당신의 성별은 무엇입니까? 1) 남성 2) 여성 |
이런 간략한 설문 조사를 통하여 10명의 응답자로부터 얻은 설문 결과를 데이타 윈도우에 정리한 것이 아래 화면입니다. 그런데 만일, 뒤늦게 학생 1명으로부터 추가적으로 설문지를 받게 되었을 때는 어떻게 해야 할까요? 우선 생각해볼 수 있는 가장 간단한 방법은 마지막 행인 11번째 행에 새로 응답을 받는 학생이 데이타를 추가하면 될 것입니다.

하지만 경우에 따라서는 특정 행에 새로 얻은 설문지를 삽입해야 하는 경우도 생깁니다. 예를 들면 데이타가 학번이나 날짜와 같이 일정한 순서를 가지고 있는 경우들입니다. 만일 첫번째 행과 두번째 행 사이에 새로 얻은 데이타를 추가하고자 할 때의 절차를 살펴보도록 하겠습니다.
1) 행을 추가하기 위해서는 추가하고자 하는 행 번호에 마우스를 왼쪽 클릭한다. 그러면 해당 행 전체가 블록으로 지정된다
2) 마우스 오른쪽 버튼을 누르거나 메뉴의 편집(E)에서 ‘케이스 삽입(I)’을 선택하면 새로운 행이 공란으로 추가되며, 공란의 각 셀은 마침표(.)로 나타납니다. 그리고 기존에 있던 행은 다음 행으로 자동적으로 밀려납니다.
3) 새롭게 생긴 행의 셀이 추가하고자하는 데이타를 입력하면 됩니다.
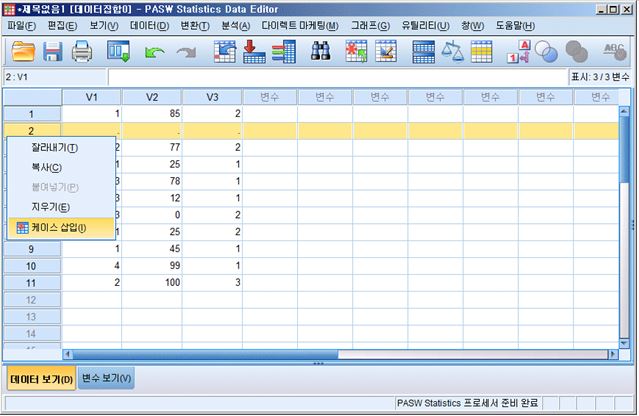
만일 설문 문항이 증가하거나 변수가 추가되었을 경우에는 어떻게 해야 할까요? 변수가 추가되었을 경우에는 열(column)을 증가시키게 되며, 그 과정은 행(raw)을 추가하는 과정과 동일합니다. 첫번째 변수로 V1이 아니고 설문지의 일련번호를 의미하는 'no'라는 새로운 변수를 추가하는 과정을 살펴보도록 하겠습니다.
1) 열을 추가하기 위해서는 추가하고자 하는 열 번호에 마우스를 왼쪽 클릭한다. 그러면 해당 열 전체가 블록으로 지정된다
2) 마우스 오른쪽 버튼을 누르거나 메뉴의 편집(E)에서 ‘변수 삽입(I)’을 선택하면 새로운 열이 공란으로 추가되며, 공란의 각 셀은 마침표(.)로 나타납니다. 그리고 기존에 있던 열은 다음 열로 자동적으로 밀려납니다.
3) 새롭게 생긴 열의 셀의 설문지의 일련번호인 1~11을 입력하면 됩니다.
3. 데이타의 정리
최근에는 온라인을 통한 설문 조사가 많이 진행되고 있습니다. 온라인으로 조사가 진행될 경우, 대부분 응답자의 응답 결과는 자동으로 SPSS에서 직접 읽어들일 수 있는 파일 포맷인 엑셀이나 txt 형태로 저장됩니다. 그 결과 응답 결과는 별다른 처리없이 신속하게 바로 SPSS에서 사용할 수 있습니다.
그러나 아직은 조사원이 직접 응답대상자를 찾아가서 설문지를 받아오는 전통적인 면대면 방식의 조사 방식이 보다 많이 활용되고 있습니다. 면대면 방식이 더 많은 시간과 비용이 소요되지만 응답자들의 협조를 구하는 것이 용이하고, 조사의 신뢰성도 더 높기 때문에 여전히 선호되고 있습니다.
이런 면대면 방식의 응답 결과는 종이로 인쇄된 설문지를 통하여 얻게되기 때문에, SPSS로 분석하기 위해서는 종이에 적힌 응답 결과를 SPSS가 인식할 수 있도록 직접 키보드를 두들겨서 데이타 윈도우에 값을 입력하거나, 엑셀 혹은 TXT 파일로 작성한 이후에 다시 SPSS로 읽어와야 합니다. 우리는 이 과정을 ‘펀칭(punching)’ 이라고 합니다.
펀칭이라고 부르는 이유는 지금은 생소하지만 60~70년대 컴퓨터 초창기에는 실제로 종이 카드에 천공기로 구멍을 뚫어서 직접 데이타를 입력했기 때문에 그런 이름이 붙었다고 합니다.
그러나, 사람의 손을 거쳐 종이에 적힌 데이타가 컴퓨터가 인식할 수 있는 디지털 파일로 바뀌는 과정에서 착오나 오타로 잘못된 정보들이 입력되는 경우들이 종종 있습니다. 데이타 정리, 혹은 데이타 클린싱(cleansing)은 이런 잘못된 데이타들을 교정해서 바로잡는 과정이라고 할 수 있습니다.
우선 아래 설문지와 입력된 데이타 파일을 비교해보면서 입력이 잘못되었다고 의심할 만한 사례가 있는지 확인해 보도록 하겠습니다.
|
문항 1. 당신이 좋아하는 과목은 다음중 무엇입니까? 1) 수학 2) 과학 3) 영어 4) 기타 문항 2. 당신의 평균 기말고사 점수는 몇 점입니까? 직접 입력하여 주시기 바랍니다. ________ 점 문항 3. 당신의 성별은 무엇입니까? 1) 남성 2) 여성 |

이미 찾으셨는지요? 이 데이타와 설문지를 비교해보면 10번째 응답자의 V3 변수에 이상이 있는 것을 알 수 있습니다. 실제 V3변수는 응답자의 성별 변수이며, 취할 수 있는 변수 값은 1=남성, 2=여성인데 입력값은‘3’입니다.
이런 오류가 나타날 가능성은 크게 두가지 입니다.
1) 설문 응답자가 실제로 틀리게 ‘3’을 쓴 경우, 혹은
2) 응답자는 1이나 2로 바르게 썼으나 펀칭 과정에서 오타가 발생한 경우입니다.
이를 확인하기 위해서는 실제 종이로된 설문지를 다시 찾아보고 응답 결과를 확인하는 수 밖에 없습니다. 확인시 해당 열에서 오름차순정렬이나 내림차순정렬을 잘 사용하면 이런 작업을 보다 손쉽게 할 수 있습니다.
만일 설문에 응답한 응답자가 수백 혹은 수천명을 넘을 정도로 너무많다면, 이중에서 잘못 펀칭한 설문지를 어떻게 찾느냐고요? 이런 경우를 대비해서 각 설문지에는 설문지 일련번호를 붙일 것을 권장하며, 관습적으로 spss 데이타의 첫번째 변수, 즉 첫번째 열에는 보통 설문지 일련 번호를 부여하게 됩니다.
4. 케이스 선택
이제 데이타의 정리까지 끝났고, 본격적으로 분석할 준비가 되어 있습니다. 그런데 경우에 따라서는 준비된 데이타를 모두 사용하지 않고 데이타 파일의 일부 케이스만 이용하여서 분석을 해야하는 경우가 있습니다.
|
문항 1. 당신이 좋아하는 과목은 다음중 무엇입니까? 1) 수학 2) 과학 3) 영어 4) 기타 문항 2. 당신의 평균 기말고사 점수는 몇 점입니까? 직접 입력하여 주시기 바랍니다. ________ 점 문항 3. 당신의 성별은 무엇입니까? 1) 남성 2) 여성 |
일예로, 위와 같은 설문조사를 통하여 조사를 완료하고 데이타를 모두 가지고 있지만, 수학 선생님이 특별히 수학과 관련된 내용을 분석하고 싶어할 수도 있고, 혹은 남자의 성적만이 궁금한 경우가 있을 수 있습니다. 이 경우 특정한 케이스만 선택하여 분석을 할 수 있게 해주는 메뉴가 ‘케이스 선택(S)' 입니다.

예로 남학생만의 기말고사 점수를 보고 싶은 경우를 중심으로, 어떤 단계를 거쳐 케이스 선택이 진행되는지 살펴보겠습니다.
1) 메뉴 바에서 ‘데이타(D)'를 선택한 후 차례로 ’케이스선택(S)'을 클릭합니다. 그려면 아래와 같이 케이스 선택 대화상자가 나타납니다. 케이스 대화상자의 왼쪽 창에서는 데이타 파일에 있는 모든 변수들을 보여주고 있습니다.
2) 여기서 선택가능한 버튼중에서 ‘조건을 만족하는 케이스(C)'를 선택한 후, 다시 바로 밑에 있는 ‘조건(I)' 버튼을 클릭합니다.
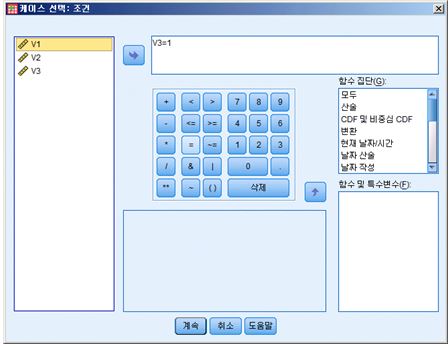
3) 조건 버튼을 클릭하면 다시 보다 작은 크기의 ‘조건 대화상자’가 나타나게 됩니다. 여기서 우리는 남학생만을 선택하여 분석할 것이기 때문에 성별을 나타내는 변수인 'V3' 변수를 클릭한 후 화살표 버튼을 눌러 우측으로 옮겨놓습니다. 그리고 변수 값을 지정하게 됩니다. v3의 변수 값을 보면 1=남자, 여자=2이므로, 'V3=1'을 입력하면 남자만 선택되게 됩니다. 입력하는 방법은 직접 키보드로 입력을 해도되고, 대화 상자 중앙의 전자계산기처럼 생긴 버튼들을 이용하여 입력하여도 됩니다.
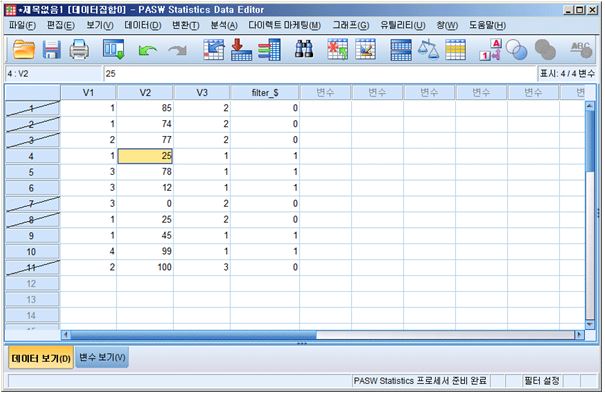
4) 자 이제 지정이 끝났습니다. 지정이 잘 끝났는지 확인하려면, 다시 데이타 윈도우로 돌아가 보십시요. 만일 모든 과정이 잘 끝났다면, 데이타 윈도우에서 v3=2, 즉 성별 변수가 여자인 경우에는 행 번호를 보여주는 첫번째 박스에 / 표시가 되어 있는 것을 볼 수 있을 것입니다. 아울러 ‘filter_S'라는 변수가 하나 더 생긴 것을 볼 수 있는데, 0인 변수 값은 분석에 사용하지 않는다는 의미이며, 변수 값이 1인 것은 분석에 사용한다는 의미입니다. 이렇게 지정이 된 이후에는 앞으로 어떤 분석을 하더라도 남자만이 분석에 포함되며 여자는 분석에서 제외될 것입니다.
5) 마지막으로, 케이스 선택은 다시 해제하지 않으면 지속적으로 앞으로의 모든 분석들에 동일한 영향을 미치게 됩니다. 따라서, 남학생을 대상으로한 분석이 끝나고, 다시 남녀 전체를 대상으로 분석을 해야할 경우에는 반드시 먼저 케이스 선택을 해제해주셔야만 합니다. 해제하는 방법은 케이스 선택 대화상자에서 ‘모든 케이스’를 선택해주시면 해제가 됩니다.
본 사례에서는 케이스 선택을 이해하기 위하여 남학생만을 선택하는 지극히 간단한 예를 사용하였습니다. 하지만, 케이스 선택 대화상자에서 제공하는 다양한 수식 기호나 함수들을 이용하여 더욱 복잡한 조건들을 사용하여 케이스를 선택하는 것도 가능합니다.
예를 들어서 평균 점수가 80점 이상인 우등생만을 대상으로 분석하고자 할때는 조건 대화상자안에 “v2 > 79'라는 간단한 수식으로 원하는 케이스만을 선택할 수 있으며, 이 수식을 조금 더 응용하면 ‘수학이 50점 미만인 남자’와 같이 여러개의 변수들을 같이 사용하여 보다 복잡한 조건을 충족하는 케이스만을 선택할 수도 있을 것입니다.
: 청주대학교 이 원준 (meetme77@naver.com)
'파보자! SPSS&Jamovi 분석 > 2. SPSS로 시작하기' 카테고리의 다른 글
| [SPSS 리서치] 7. 데이타 변환 및 리코딩 (7) | 2019.11.14 |
|---|---|
| [SPSS 리서치] 5. SPSS 데이터 입력 및 변수 정리 (8) | 2019.10.23 |