1. 분산분석의 필요성
분산분석(ANOVA: Analysis of Variance)은 두 개 이상 집단 간의 평균에 대한 차이를 검정하는 통계분석입니다. 분산분석을 이용하여 각 집단들이 동일한 평균을 가진 모집단에서 추출된 것인지 여부를 검정할 수 있습니다. 예를 들어서 광고 모델을 누구로 사용하는가에 따라서 광고에 대한 평가가 달라질 수 있습니다. 즉 어떤 사람은 아이돌같은 연예인들이 등장하는 광고에 호감을 보이는 반면, 다른 사람들은 일반 보통사람들이 등장하는 광고에 더 큰 호감을 느끼기도 합니다. 이러한 상황에서 마케팅 관리자는 소비자들이 어떤 광고 모델에 더 좋은 반응을 나타내는지를 알고 싶을 것입니다. 분산 분석은 이와 같이 마케팅 전략의 효과 측정이나 소비자 집단의 마케팅 전략에 대한 반응 차이 등에 대하여 통계적으로 검증된 의사결정을 가능하게 합니다.
2. 분산 분석의 이해
집단간의 평균에 통계적 차이가 있다 혹은 없다는 것을 어떻게 측정할 수 있을까요? 분산 분석의 기본 원리를 이해하기 위하여 가상적인 A기업의 신상품 홍보 전략을 예로 설명하고자 합니다.
A회사는 새로운 여성용 화장품 브랜드를 런칭하면서, 브랜드를 널리 알리기 위하여 향수 샘플, 현금할인, 그리고 무료 마사지의 3 가지 판촉물을 준비하고 있습니다. 그리고 이중 어떤 판촉물이 더 효과적인지 확인하기 위하여 전국에 분포되어 있는 12개의 점포를 각각 4개의 점포로 나누어 총 3개의 집단을 구성하였습니다. 각각의 집단에는 한 가지 종류씩 판촉물이 주어졌으며, 1개월의 판촉 행사가 종료된 이후 다음과 같은 판매 성과를 얻었습니다.
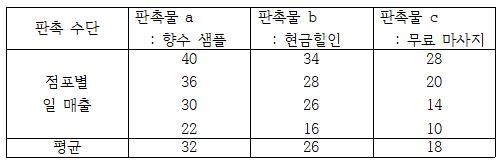
이와 같은 결과를 받은 후에 A기업은 어떤 각기 다른 3가지 판촉수단을 사용한 3개 집단간에 통계적으로 유의한 차이가 있는지를 분석하여 의사결정에 활용할 수 있는데 이를 분산분석이라고 합니다.
분산분석에서는 독립 변수와 종속 변수가 각각 필요합니다. 독립변수는 서로 다른 판촉 수단을 사용한 향수 샘플, 현금 할인, 무료 마사지의 3개 집단이 되며, 종속 변수는 이들 각 집단의 일평균 매출액이 됩니다. 즉 독립변수는 명목이나 비율 척도로서 그 값이 변하지 않고 항상 일정하지만, 종속변수는 등간이나 비율 척도로서 어떤 독립변수를 기준으로 평균을 파악하는가에 따라서 수시로 그 값이 변할 수 있습니다.
분산분석에서 사용하는 귀무가설과 대립 가설은 다음과 같습니다.
H0 : 집단별 매출액은 동일하다
H1 : 집단별 매출액은 동일하지 않다
3. 분산분석의 계산 절차
분산분석은 전체 분산을 이루고 있는 집단간 분산과 집단내 분산 중에서 집단 간 분산이 집단내 분산보다 얼마나 큰가를 판단하여 집단 간의 차이를 검정하는 방식입니다. 따라서 가설을 검증하기 위하여 분산분석에서는 집단내 분산, 집단간 분산, 그리고 전체 분산의 3가지 분산을 계산해야만 합니다.
1) 집단내 분산
집단내 분산은 각 집단의 평균치를 중심으로 집단내 각 측정치들이 얼마나 떨어져 있는 가를 나타내며 집단내 분산은 무작위 오차에 의한 것입니다. 즉 집단의 특성에 의한 차이가 아니라 그 외 설명할 수 없는 원인들에 의한 차이들입니다. 일예로 향수를 사용한 a 집단의 평균 매출은 32만원이지만, 같은 a 집단내에서도 매출액은 22만원 ~ 40만 원까지 다양합니다. a 집단내에서 발생한 매출 차이는 동일한 판촉 수단을 썼으므로 결코 판촉 수단의 차이가 될 수 없으며, 판촉 수단 이외의 알지 못하는 원인에 의해 발생한 차이임을 의미합니다. 집단내 분산을 구하기 위한 공식은 다음과 같습니다.

이를 앞의 A기업의 판촉 예에 대입해보면 집단내 분산은 다음과 같이 구할 수 있습니다.
판촉물 a(향수샘플) 집단내 분산= (40-32)2 + (36-32)2 + (30-32)2 + (23-32)2 = 184
판촉물 b(가격할인) 집단내 분산= (34-26)2 + (28-26)2 + (26-26)2 + (16-26)2 = 168
판촉물 c(무료 마사지) 집단내 분산= (28-18)2 + (20-18)2 + (14-18)2 + (10-18)2 = 184
** 그리고 이 세개 집단의 집단간 분산을 모두 합산한 전체 집단내 분산은 184+168+184 = 536 입니다.
2) 집단간 분산
집단간 분산은 각 집단들의 평균이 전체 평균으로부터 떨어져 있는 정도로 계산됩니다. 이는 집단의 특성에 따른 차이로써, 3개의 집단이 각기 다른 판촉 수단을 사용하였기 때문에 발생한 차이라고 볼 수 있을 것입니다. 집단간 분산을 구하기 위한 공식은 다음과 같습니다.

이를 앞의 A기업의 판촉 예에 대입해보면 집단간 분산은 다음과 같이 구할 수 있습니다.
** 집단간 분산= 4( (32-25.3)2 + (26-25.3)2 + (18-25.3)2 ) = 394.7 입니다.
3) 전체 분산
전체 분산은 각 측정치들이 전체 평균에서 얼마나 떨어져 있는가의 정도이며,
전체분산 = 집단간 분산 + 집단간 분산 = 536 + 394.7 = 930.7 로 구할 수 있습니다.
이제 구해진 집단내 분산과 집단간 분산을 이용하여 집단간 차이를 분석하기 위해서는 추가적으로 각각의 분산 값들을 자유도로 나누어 줌으로써 ‘평균 분산(M.S)'을 구하여야 합니다. 세가지 분산별 자유도를 구하는 방식은 다음과 같습니다.
ㅇ 집단내 분산의 자유도 = (집단의 수 * 집단내 항목 수) - 집단의 수
= (3 * 4) - 3 = 9
ㅇ 집단간 분산의 자유도 = 집단의 수 – 1
= 3 - 1 = 2
ㅇ 전체 분산의 자유도 = 집단내 분산의 자유도 + 집단간 분산의 자유도
= 9 + 2 = 11 입니다.
이미 구해진 분산값을 각각의 자유도로 나눌 경우, '평균분산(MS)'를 구할 수 있습니다.
ㅇ 집단내 평균분산 = 536 / 9 = 59.6
ㅇ 집단간 평균분산 = 394.7 / 2 = 197.3
마지막으로 구해진 평균분산 값을 이용하여 집단간에 평균 값의 차이가 있다는 것을 검증하기 위하여 집단간 분산이 집단내 분산보아 얼마나 큰지 F 검정을 해야 합니다. F 검정은 집단간 평균분산을 집단내 평균분산으로 나누어준 F 값을 가지고 검정이 이루어 집니다.
ㅇ F 값 = 집단간 분산 / 집단내 분산
= 197.3 / 59.6 = 3.31
즉 이런 과정을 통하여 도출된 F 값을 F비율통계표의 특정 유의수준별 제시된 통계량과 비교함으로서 가설의 기각이나 채택 여부를 결정하게 됩니다. 즉 이런 과정을 거쳐서 나온 F 값인 3.31은 유의수준 0.10에서 확인할 수 있는 임계치인 3.01보다 더 크므로 “H0(귀무가설) = 집단간의 매출액은 동일하다”는 당초의 귀무 가설은 기각이 되며, 그 반대인 대립가설이 채택되빈다. 즉 집단간 유의한 차이가 있다고 판단하게 되는 것입니다. 실제 SPSS에서는 이런 비교의 번거로움을 덜어주기 위해서 F 값과 더불어 검정 결과를 유의도 값으로 제공합니다.
4. 분석을 위한 설문과 데이타
실제로 분산분석은 집단간 평균 차이를 구하기 위한 여러 방법의 총칭이며, 보다 세부적으로는 일원 분산분석, 다변량 분산분석 등 다양한 형태가 존재합니다. 본 차시에서는 분산 분석중 가장 기본적 방법이라고 할 수 있는 일원 분산분석(One-way ANOVA)를 중심으로 설명드리도록 하겠습니다.
일원 분산분석은 단 하나의 독립 변수에 의하여 발생하는 종속변수의 평균 차이를 검정합니다. 독리변수는 반드시 명목이나 서열 척도로 측정되어야 하며, 종속변수는 등간이나 비율 척도로 측정된 자료여만 합니다. 이를 위배할 경우 앞에서 살펴본 바와 같은 분산이나 F 값을 구할 수 없으므로 분산분석을 시행할 수 없습니다.
우선 분산분석을 실습하기 위하여 어떤 문항들을 사용할지 실습용 설문지를 참조해 보도록 하겠습니다. 본 분석에 사용될 설문 문항은 월평균 소득을 묻는 7번 문항과 집에서 보유한 TV의 사이즈를 묻는 문항을 사용하도록 하겠습니다. 즉 소득에 따라 TV 사이즈에 유의한 차이가 있는지 평균을 비교해보고자 합니다. 각 문항들을 살펴보면 7번 문항은 집단을 구분하는 변수로서 명목척도로 구성되어 있는 독립변수이며, 10번 문항은 비율 척도로 구성된 종속 변수 임을 알 수 있습니다.

5. 분산 분석 및 결과
이제 ‘실습 설문지와 실습 data를 이용하여 직접 SPSS를 이용한 분석을 해보도록 하겠습니다. 우선 데이타 파일을 여신 후, 월평균 소득과 TV의 크기 변수들을 확인하십시요.
1) 분산분석 메뉴의 실행
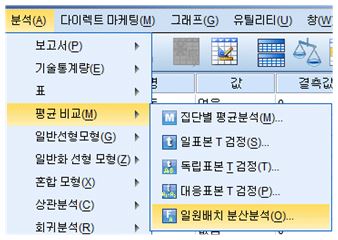
분산 분석을 수행하기 위해서는 우선 메뉴 바의 분석(A) -> 평균비교(M) -> 일원배치 분산분석(O)을 차례데로 클릭해주시기 바랍니다. 이를 모두 실행하면 분산분석 대화상자가 나타납니다.
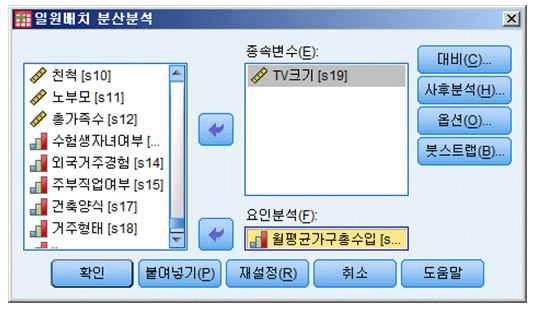
2) 분석 대상 변수의 선택
분산분석을 클릭한 경우 아래 그림과 같이 일원배치 분산분석 대화창이 나타납니다. 분산분석에서는 종속변수와 독립변수를 각각 구분지어서 지정해주어야 하는데, 대화창에서 나타난 ‘요인 분석’에 독립변수를 지정해주면 됩니다. 본 분석에서는 명목척도로 측정된 가구총수입을 독립변수로, 비율척도로 측정된 TV크기를 종속변수로 지정함으로서, 가구 수입별 집단에 따라 TV의 사이즈에 차이가 있는지 검정할 것입니다.
3) 옵션의 조정
: 분산 분석은 별도의 옵션을 지정하지 않더라도 충분히 필요한 정보들을 제공하기 때문에 옵션을 따로 조정할 필요는 많치 않습니다. 하지만 대화창 우측의 ‘옵션’버튼을 눌러보시면 기술 통계 등 몇몇 옵션을 선택할 수 있습니다. 본 실습에서는 기술 통계 옵션만을 선택하고 바로 분석을 진행해보도록 하겠습니다.
4) 분석의 시행 및 결과
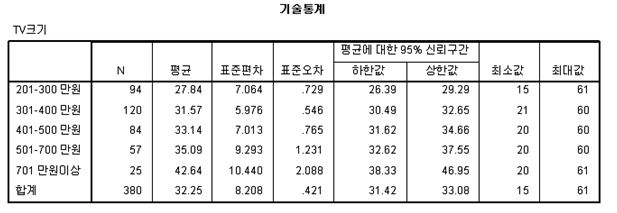
이제 분산분석을 시행해보도록 하겠습니다. 옵션에서 기술통계를 선택하였기 때문에 분산분석은 먼저 각 집단의 평균적인 TV 사이즈 정보를 제공합니다. 분산분석의 목표가 집단간 평균 비교이기 때문에 평균을 표시하는 기술 통계 옵션은 항상 선택하시는 것이 좋습니다.
집단간 평균 차이를 보면 확실히 소득이 올라갈수록 TV의 사이즈도 같이 증가하는 것을 볼 수 있습니다. 일예로 소득 300만원 미만의 평균 사이즈가 고직 27.8인치에 불과하였지만, 701만원 이상인 경구 그 사이즈가 42.6인치로 증가하고 있습니다. 그러나 이 결과만을 가지고는 이 차이가 통계적으로 유의한지 확신할수는 없습니다. 이제 분산분석표를 확인할 차례입니다.
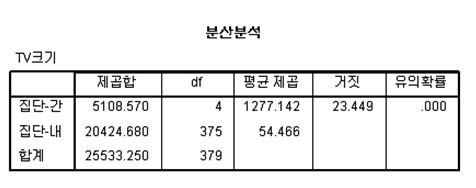
그 바로 다음의 결과는 요약된 분산분석표를 보여줍니다. 분석표에는 분산의 제곱합, 자유도(df), 평균제곱, F값, 유의확률 등의 값을 보여주고 있습니다. SPSS 프로그램을 한글화하는 과정에서 번역이 잘못되어 F 값이 ‘거짓’으로 오역되어 있는 것도 볼 수 있습니다. 이처럼 통계 용어의 오번역등의 여러 이유로 많은 SPSS 사용자들은 한글보다는 영문 버전을 선호하기도 합니다.
결과에 따르면 집단간 평균과 집단내 평균을 이용하여 구한 F 값은 23.499이며, 유의확율은 0.000으로 나타나고 있습니다. 유의확률은 보통 p값, sig 등 다양한 형태로 표시되기도 하는데, 가설 검증을 통하여 상관계수가 통계적으로 유의한가에 대한 정보이며, 보통 그 기준은 유의확률이 0.05보다 작은 경우 통계적으로 유의하다고 판단합니다. 분석 결과 유의 확율은 0.000으로서 통계적 유의성이 확보되었습니다. 즉 소득 집단별 보유한 TV의 크기는 유의한 것으로 나타나고 있습니다.
* 본 강좌 내용을 보다 상세히 동영상으로 보고싶으신 분들은 아래 유튜브 강좌 참조하세요.
: 청주대학교 이 원준 (meetme77@naver.com)
'파보자! SPSS&Jamovi 분석 > 3. SPSS로 분석하기' 카테고리의 다른 글
| [SPSS 리서치] 11. 상관관계 분석 (correlation) (8) | 2019.11.28 |
|---|---|
| [SPSS 리서치] 10. 다중응답(multiple choice) 분석 (7) | 2019.11.23 |
| [SPSS 리서치] 9. 교차(Cross-tab) 분석 (8) | 2019.11.23 |
| [SPSS 리서치] 8. 빈도 및 평균 분석 (10) | 2019.11.17 |