1. 상관관계 분석의 필요성
상관관계(correlation) 분석은 연구 대상인 변수들간의 관련성을 분석하기 위하여 사용됩니다. 즉 한 변수와 다른 변수와 어느 정도 관련성을 가지고 같이 변화하는지의 정도를 분석하는 목적으로 사용됩니다. 예를 들어서 광고량과 판매량을 각각 비율척도로 입력하여 상관관계 분석을 하거나, 광고량(광고비로 입력한 비율척도)과 제품에 대한 만족도(5점 등간 척도)를 대상으로 상관관계 분석이 이루어질 수 있습니다. 이처럼 두개 변수간의 상관관계를 나타내는 것을 ‘단순상관관계’라고 합니다. 단순상관관계를 분석하는 것만으로도 관리자는 효과적인 의사결정에 필요한 기본적 자료를 얻을 수 있습니다. 일예로 만일 광고량과 제품에 대한 만족도간에 별다른 관련성이 없다면, 고객의 불만이 증가할 때 광고를 늘리는 것은 그다지 현명한 전략이 아닐 것입니다.
상관관계의 분석에 사용되는 변수들은 반드시 등간척도나 비율척도처럼 연속성을 가지고 있는 변수들을 가지고 분석이 이루어집니다. 즉 자동차의 모델명(명목척도)과 연비(비율척도) 간의 상관관계는 이루어질 수 없습니다. 그 이유는 명목 척도는 평균이나 분산을 가질 수 없으므로, 통계적 추정이 필요한 상관관계가 불가능하기 때문입니다.
2. 상관관계 분석의 이해
변수들간의 관련성이 높다 혹은 낮다는 것은 어떻게 측정이 가능할까요? 변수들간의 상호관련성, 즉 상관은 특정 변수의 분산이 다른 변수의 분산과 같이 변화하는 정도에 따라 결정됩니다. 이처럼 같이 같이 공명하며 변동하는 분산을 공분산이라고 합니다.
아래 그림에서 보듯, 같이 변동하는 정도가 적을수록 상관관계는 낮아지면, 같이 변동하는 정도가 클수록 상관관계는 높아집니다. 이때 상관관계의 정도를 나타내주는 것이 상관계수인데, 전혀 상관이 없을 경우의 상관계수는 0이지만, 완전히 변동하는 부분이 일치하는 경우의 상관계수는 -1 혹은 1입니다. 즉 상관계수는 -1 ~ 1 사이의 값을 같습니다.

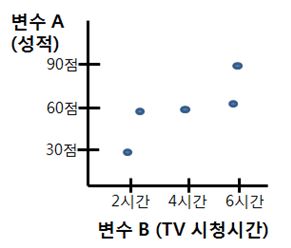
제시된 산포도를 기준으로 가상적 예를 살펴보면, 학생의 학습시간에 따라 성적이 정확하게 비례하여 증가하는 경우 +1의 완전한 상관관계를 보이고 있지만, 시외버스의 운행 간격과 성적은 상관관계가 거의 존재하지 않는 0의 상관관계를 보입니다. 반면에 학생의 온라인 게임을 즐기는 시간에 비례하여 성적이 정확하게 감소하는 경우 -1의 상관관계를 보이고 있습니다.
그러나 현실 세계에서는 이렇게 +1 혹은 -1의 완전한 상관관계를 보이거나 상관계수가 0인 전혀 상관이 없는 관계는 그렇게 많치 않습니다. 그보다 대부분의 경우는 다소의 상관관계를 가지고 있는 것이 보통입니다. 아래의 가상적 예에서 보듯 대부분의 상관관계는 어느 정도의 강도를 가지고 움직이는 것이 보통입니다. 상관계수의 절대값이 0.2이하면 보통 상관관계가 무시할 수 있을 정도로 미약하다고 판단하며, 02 ~ 0.6 정도면 어느정도 상관관계가 있다고 인정됩니다. 그리고 0.6 이상일 경우 매우 강한 상관관계가 있는 것으로 인정됩니다.
또한 상관계수의 값을 제곱한 것을 ‘결정 계수’라고하며, 이 결정 계수 한 변수가 다른 변수의 변화를 설명할 수 있는 설명력을 의미합니다.
3. 상관관계 계산의 절차
상관관계 계산의 기초적 절차로서 우선 ‘공분산’의 개념을 이해하여야 합니다. 공분산이란 확률변수 X의 증감에 따라 또 다른 확률변수 Y가 증감하는 정도로서, 의 기대값이며 기호로는 cov(X, Y)로 표시합니다. 그러나 위 식에서 보듯, 공분산은 X와 Y의 단위가 커지면 자연스럽게 같이 증대하게 되므로, 공분산을을 표준화할 필요가 있습니다. 이 공분산을 표준화한 것이 상관계수입니다. 즉, 상관계수는 다음과 같으며 -1 ~ 1 사이의값을 갖게 됩니다.

: 1) x와 y의 공분산, 2) x의 표준편차, 3) y의 표준편차
이를 보다 잘 이해하기 위하여 실제 사례를 가지고 같이 상관계수를 구해보도록 하겠습니다.
[사례]
스마트폰을 제작하는 S사는 최근 신제품을 개발하면서 스마트폰 가격이 커짐에 따라 더 많은 고객들이 좋은 평가를 내리는 것을 알게 되었습니다. 이런 경험을 통해서 막연하지만 스마트폰의 높은 가격 이미지가 판매량에 좋은 영향을 주고 있는 것이라고 생각을 하게 되었습니다. 이런 관계를 검증하기 위해서 가격 판매량간의 과거 데이타를 분석하여 그 관계를 파악하고자 합니다.

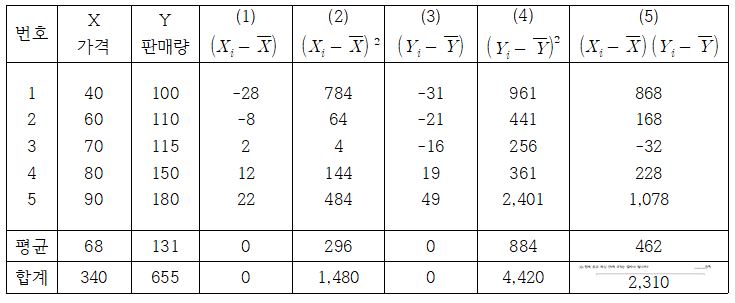
a. 상관계수를 구하기 위해서는가격(X)과 판매량(Y) 변수의 평균 및 합계를 구해야 합니다. 그 결과는 다음과 같습니다.
b. 구해진 각 변수의 평균을 활용하여 1), 2), 3), 4)를 구합니다. 즉 각 관측치에서 각 변수의 평균을 차감한 값을 활용하여 (1)과 (3)을 각각 구한뒤, 이 값들을 제곱하여 (2)와 (4)를 구한 후 다시 (5)를 구하십시요. 이때 2)와 4)는 곧 가격(X)과 판매량(Y) 각각의 표준편차이며, 5)는 이 두개 변수의 공분산입니다.
c. 상관계수 구하기
이제 가격(X)과 판매량(Y) 각각의 표준편차를 알고 있으며, 이들 변수간의 공분산을 알게 되었습니다. 이를 활용하면 바로 상관계수를 구할 수 있습니다.
즉,
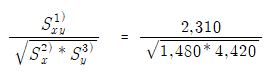
= 0.903의 높은 상관관계가 있는 것으로 나타났습니다. 이 결과의 의미는 스마트폰의 가격과 판매량간에 매우 강력한 상관관계가 존재한다는 것을 의미합니다.
4. 분석을 위한 설문과 데이타
이처럼 직접 계산을 하여서 상관계수를 구하는 것도 가능하나, SPSS는 이런 중간 단계를 생략하고 바로 상관 관계를 구할 수 있는 편리한 기능을 제공합니다. 즉, 통계적인 지식이 없다고 하더라도 등간척도와 비율척도를 활용하여 매우 간단하게 상관관계를 구할 수 있습니다.
우선 이를 실습하기 위하여 어떤 문항들을 사용할지 실습용 설문지를 참조해 보도록 하겠습니다. 본 분석에 사용될 설문 문항은 설문 22페이지의 가족의 숫자를 묻는 4-9)번 문항과 집에서 보유한 TV의 사이즈를 묻는 10번 문항을 사용하도록 하겠습니다. 즉, 가족이 많으면 많을수록 더 편리하게 보기 위하여 더 큰 사이즈의 TV를 구하고 싶어할 것이라는 가설을 검증해보고자 합니다.

이 두개의 문항은 모두 비율척도로서 상관관계의 분석에 적합한 것으로 판단되었습니다. 추가로, 소득수준 역시 TV의 크기에 영향을 미칠 것이라고 가설을 세울 수 있습니다. 당연히 소득이 많을수록 소비지출이 많으므로 누구나 생각해볼만한 가설입니다. 그러나 소득 수준을 물어보는 22페이지의 문항 7을 살펴보니, 명목척도로 물어보고 있습니다. 충분히 소득수준과 TV의 크기간에는 유의한 상관관계가 실제로 존재하더라도, 조사자가 소득을 이처럼 명목 척도로 물어보았다면 상관관계를 진행할 수 없습니다. 따라서 어떤 연구 방법을 사용할지 여부는 설문지 작성 단계에서부터 고민되고 결정될 필요가 있음을 알 수 있습니다.

만일 소득 수준을 응답자가 직접 넣도록 하는 비율형 척도를 사용하였다면, 이 두변수간의 상관관계 분석은 가능했을 것입니다. 즉, 아래와 같이 물어보았다면 당연히 상관관계 분석이 가능합니다.

5. 상관관계 분석 및 결과
이제 직접 SPSS를 이용한 분석을 해보도록 하겠습니다. 우선 데이타 파일을 여신 후, 가족 수와 TV의 크기와 관련된 변수들을 확인하십시요. 단순상관관계 분석을 위해서는 최소한 2개 이상의 변수가 필요합니다. 만일 변수가 2개 이상인 경우에는 자동적으로 모든 변수의 쌍대 조합을 이용하여 모든 가능한 상관관계 변수를 자동으로 분석해줄 것입니다.
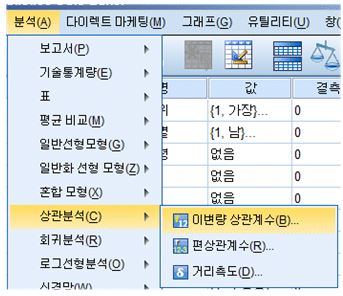
1) 상관분석 메뉴의 실행
상관관계 분석을 수행하기 위해서는 우선 메뉴 바의 분석(A) -> 상관분석(C) -> 이변량 상관계수(B)를 차례데로 클릭해주시기 바랍니다. 이를 모두 실행하면 상관분석 대화상자가 나타납니다.
2) 분석 대상 변수의 선택
아래 그림과 같이 대화상자에서 분석할 변수인 ‘가족 수(변수명: s12)’와 ‘TV의 크기(변수명: s19)’를 선정한 후 화살표를 클릭해서 오른쪽의 변수(V) 상자로 보냅니다.

대화상자를 보면은 Pearson 상관관계 분석으로 지정되어 있는 것을 볼 수 있습니다. 피어슨 상관관계는 바로 위에서 공분산과 표준편차를 이용하여서 구하였던 상관계수와 동일하기 때문에 이를 그대로 놓아두시고 그대로 진행합니다.
3) 옵션의 조정
: 바로 ‘확인’ 버튼을 누르는 것만으로도 성공적으로 상관관계 분석이 완수되지만, 필요시 선택적으로 분석에 필요한 다양한 옵션들을 지정할 수 있습니다. 간략히 어떤 옵션들이 주요 옵션들 위주로 있는지 살펴보도록 하겠습니다.
먼저 ‘옵션’ 버튼을 클릭해보시기 바랍니다. 평균과 표준편차, 공분산등을 추가로 선택할 수 있으며, 기본적으로 결측값이 상관계수 계산시 제외되도록 되어 있습니다. 추가로 필요한 부분이 있으면 선택하신 후 다음 단계로 진행합니다.
4) 분석의 시행 및 결과
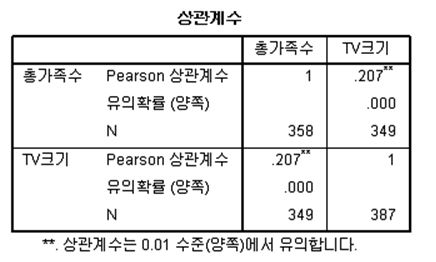
이제 상관관계 분석을 시행해보도록 하겠습니다. 도출된 상관계수 표를 보면 크게 상관계수, 유의확율, 그리고 응답자의 수(N)라는 3가지 정보를 주고 있습니다. 우선 상관계수는 0.207로서, 약한 상관관계가 있음을 알 수 있습니다. 그 다음 정보는 유의확율입니다. 유의확률은 보통 p값, sig 등 다양한 형태로 표시되기도 하는데, 가설 검증을 통하여 상관계수가 통계적으로 유의한가에 대한 정보이며, 보통 그 기준은 유의확률이 0.05보다 작은 경우 통계적으로 유의하다고 판단합니다. 분석 결과 유의 확율은 0.000으로서 통계적 유의성이 확보되었습니다.
: 청주대학교 이 원준 (meetme77@naver.com)
'파보자! SPSS&Jamovi 분석 > 3. SPSS로 분석하기' 카테고리의 다른 글
| [SPSS 리서치] 12. 분산분석 ANOVA (14) | 2019.12.05 |
|---|---|
| [SPSS 리서치] 10. 다중응답(multiple choice) 분석 (7) | 2019.11.23 |
| [SPSS 리서치] 9. 교차(Cross-tab) 분석 (8) | 2019.11.23 |
| [SPSS 리서치] 8. 빈도 및 평균 분석 (10) | 2019.11.17 |