[Jamovi 통계] 4. 기술통계와 그래프 그리기
데이터 입력 과정을 잘 이해하고, 코딩까지 마친 이후에는 이들 데이터를 가지고 본격적인 분석을 시행하게 된다. 이하 별도의 다른 안내가 없을 시, 향후 본 jamovi 실습의 데이터는 여러분이 3장에서 직접 입력한 '코로나 바이러스 이후의 소비자 행동'에 관한 실제 설문자료를 사용하게 될 것이다(본 데이터의 변수 정의와 설문문항은 3장 참조: https://sooupforlee.tistory.com/138?category=882298).
1) 기술통계란?
기술 통계는 표본 자체의 속성을 파악하여 묘사는데 주안점을 두고 있는 분석 방법이며, 기술을 의미하는 description은 이를 잘 표현한다. 기술통계는 주로 표본에 속한 대상자들의 인구통계적 특성이나 데이터가 보여주는 공통적 특성을 요약하여 보여주는 것이 주목적이다. 이를 통하여 방대한 데이터도 합리적으로 요약하고 정보처리의 수고를 덜 수 있다. 일예로, 우리는 미국인들은 진취적이며, 프랑스인들은 예술을 사랑한다고 생각한다. 물론 미국인들중에도 소극적인 사람도 있고 프랑스인들중에도 예술에 무관심한 사람들이 적지 않을 것이다. 우리는 이런 예외가 항상 적지않게 있음을 충분히 알고 있음에도 불구하고, 이들의 국민성을 한 눈에 파악할 수 있는 정보가 유용하다는 것 역시 잘 알고 있다. 나중에 어떤 통계분석을 하더라도 기술통계를 통하여 표본 전체의 전반적인 속성을 정확하게 파악하는 것은 거의 모든 통계분석의 기초가 된다.
여러가지 기술통계량이 있지만, 주요한 통계량으로는 가) 중심경향성, 나) 산포도, 다) 분포, 라) 백분위수 정도가 이용된다. 각각의 설명은 다음과 같다. ** 본 기술통계량이 중요한 이유는 대학원이나 연구기관의 학술적인 데이터 분석인 경우를 제외하고, 일상적인 데이터 분석이나 소비자 조사 등 리서치에서는 대부분의 데이터 분석들이 기술통계량을 위주로 이루어진다는 점이다. 기술통계량은 분석 자체도 쉽지만, 수학이나 통계에 대한 지식이 없어도 직관적으로 이해가능하기 때문에 사실상 거의 대부분의 일상적 기업실무에서는 기술통계만이 쓰이는 경우도 적지 않다. 물론 회귀분석이나 신경망 분석도 고도의 통계분석의 사용도 증가하고는 있지만, 이는 나중에 필요하다면 추가로 배워나가면 될 뿐이다.**
가) 중심 경향성
: 중심 경향성이란 용어 그대로 데이터가 중심을 중심으로 퍼져있는 경향을 나타내는 통계량이다. 일예로 100명이 본 시험 점수가 0점부터 100점까지 고르게 분포되어 있다면, 우리는 대부분의 사람들, 특히 중간에 속한 사람의 점수는 0점이나 100점이 아니라는 것을 안다. 기술통계량은 이 중간에 속한 사람이 누구인지 확인하게 도와준다. 이를 확인할 수 있는 대표적인 값은 여러가지가 있는데, 우선 평균(mean), 중위수(median), 최빈값(mode)이다. 평균은 이미 익숙한 개념이고, 중위수는 100명의 성적 서열(순서)을 매겼을때 가장 가운데 위치한 사람의 점수를 의미하는 값이다. 반면에 최빈값은 100명의 성적중 가장 많이 발견되는 빈도의 값이다.
나) 산포도
: 산포도는 표본의 속성을 나타내는 데이터가 퍼져 있는 정도를 설명하는 통계량으로서 최대값, 최소갑, 범위, 분산, 표준편차, 표준오차 등이 있다. 이중 최댓값(maximum)과 최소값(minimum)은 각각 데이터에서 가장 작은 값과 가장 큰 값을 나타내며, 범위(range)는 최대 및 최소값 간 차이, 즉 '최대값-최소값'을 나타낸다. 그러나 이 세 가지 통계량은 여전히 데이터의 전반적인 흩어짐과 변화량에 대한 정확한 정보를 제공해 주지 못한다. 일예로 두 학급의 평균이 70점으로 동일하더라도, A반은 성적 분포가 0점~100점까지 극단적이고, B반은 성적이 60-80점 사이로 큰 차이가 없을 수 도 있다. 이런 데이터의 흩어짐 정도에 대한 정보가 없다면 우리는 어떤 교사가 더 편애없이 잘 지도했는지 알기가 어려울 것이다. 이를 위해 또 다른 산포도 통계량, 즉 분산, 표준편차, 그리고 표준오차가 필요하다. 분산, 표준편차, 그리고 표준오차는 기본적으로 각 데이터가 평균으로부터 떨어진 거리들에 대한 평균 개념으로 이해하면 무방하다. 자세한 설명은 본 과정의목표를 넘어가므로 생략하며, 통계원론 등에서 찾아보기 바란다.
다) 분포
: 데이터 분포의 형태와 대칭성을 보여주는 통계량으로, 보통, 첨도(Kurtosis)와 왜도(skweness)를 본다. 첨도는 데이터의 정규분포도가 뾰족한 정도를, 왜도는 데이터의 분포가 뾰족한 정도를 보여준다.
라) 백분위수
: 데이터를 4분위의 집단으로 나누고 각각에 해당되는 퍼센트를 보여준다
2) Jamovi 기초적인 기술통계
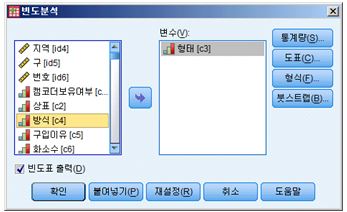
본 조사에 응답한 응답자의 성별 여부를 확인하여 우리는 남성과 여성의 %, 그리고 응답자의 평균적인 연령을 각각 살펴볼 것이다. 이를 위하여 우선 기본적인 기술통계를 위하여 '데이터546명.omv'라는 데이터 파일을 우선 연다. 그 이후의 단계는 간단하다. 상단의 '어날리세스' 메뉴 탭을 선택하고, 'Exploration(탐색)' -> 'Descriptives(기술)'을 차례로 선택한다. 그러면 다음과 같은 형태로 분석 창이 변화될 것이다. 기술통계의 기술은 '묘사하거나 서술한다(descript)'는 의미로 사용되고 있음을 알 수 있다. 즉 데이터를 요약하여 어떤 응답을 했는지 함축적으로 보여주는 매우 기초적인 분석이며, 주로 평균이나 빈도(%)의 형태로 데이터를 함축적으로 보여준다.

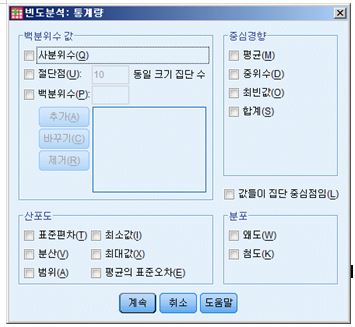
Jamovi는 분석과 결과보여주기 모두 매우 직관적인 방식을 택하고 있다. 분석 화면의 좌측에는 분석이 가능한 모든 변수들(변수 전체)를 보여주고 있는데, 이중 분석하고 싶은 변수들만 화면 우측의 'Variables'에 클릭하여 가져자 놓으면 된다. 그러면 친절한 Jamovi는 어떤 결과 값이 나왔는지를 실시간으로 바로 보여주게 된다. 화면의 'split by'는 분석값을 특정한 기준을 중심으로 나누어보고 싶을때 사용하는 메뉴이며, 이는 추후에 설명한다. 바로 그 아래에는 'Frequency table' 옵션을 지정할 수 있으며, 지정 시 빈토(%) 결과값을 보여준다. 추가적으로 분석 화면의 하단에 보면 두개의 옵션 메뉴가 숨겨져 있다. 즉 'Statisics'와 'Plots'이다. 우선 'Statisics'를 클릭하면 평균, 최빈값, 중앙값, 분포값, 퍼센타일 값등 다양한 추가 통계자료를 보여준다. 'Plots'은분석결과를보기좋은그래프형태로보여준다.
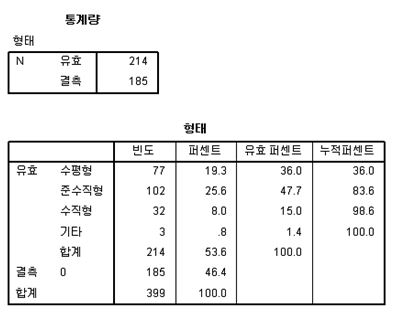
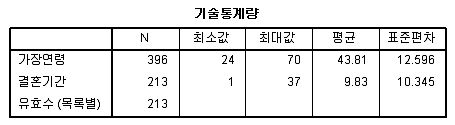
우선 테스트로 응답자의 평균 연령을 살펴보자. 이를 위해서는 단지 분석가능한 변수들중에서 연령(age)를 'Variable'창에 옮겨다 놓으면 된다. 결과값은 자동으로 산출된다. 추가적으로 응답자 성별(gender)를 분석해보자. 남녀 성별을 평균으로 본다는 것은 결과 값은 기계적으로 나오긴 하지만 아무런 의미가 없다. 이 경우 gender 변수를 'Variable'창에 옮겨놓은다음 아래의 'Frequency table' 옵션창을 클릭하면 된다. 추가적 통계옵션이 필요한 경우에는 옵션창에서 추가로 선택할 수도 있다.
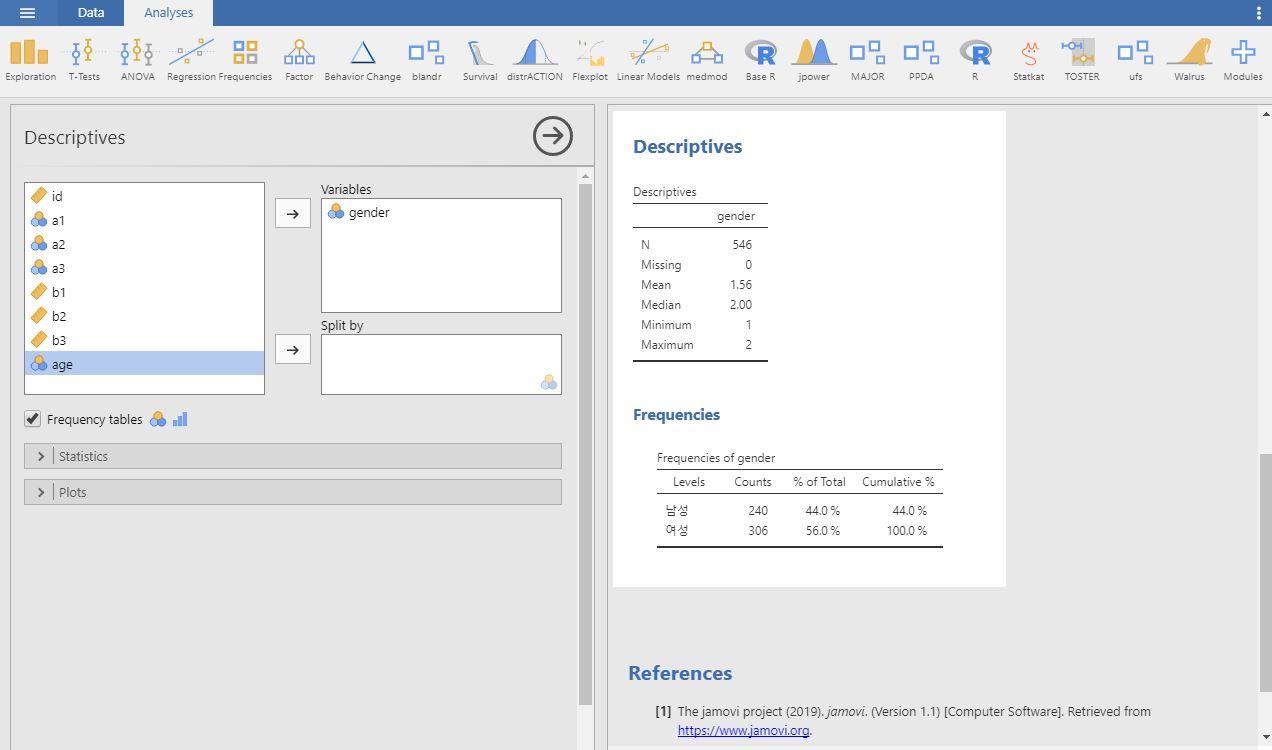
분석 결과를 보면 Jamovi의 오른편 화면에 원하는 통계결과와 관련된 참고문헌이 실시간으로 나타나는 것을 볼 수 있을 것이다. 이로서 간단한 평균이나 빈도(%)의 분석을 할 수 있게 되었다. 분석해보고 싶은 다른 변수들이 있으면 자유롭게 분석해본다. 이를 통하여 우리는 척도의 특성(명목, 등간, 비율 등)에 따라서 어떤 분석방법이 적합한지, 혹은 적합하지 않은지 앞서 배운 내용을 상기하면서 체험할 수 있을 것이다. 일예로, 그래프(plots) 작성은 데이터 특성이 적절하지 않으면 옵션에서 지정을 하더라도 그래프를 산출해주지 않을 것이다(중국집에서 스테이크를 주문하는 경우를 생각해보자. 주문하더라도 결코 스테이크는 나오지 않는다).