Textom으로하는 웹 스크래핑 Big data 분석
1. 데이터 분석
정제된 데이터의 분석 결과는 텍스트 마이닝, 매트릭스, 담론 분석, 감성분석, 토픽분석, 시계열 분석의 형태로 분석이 진행된다.
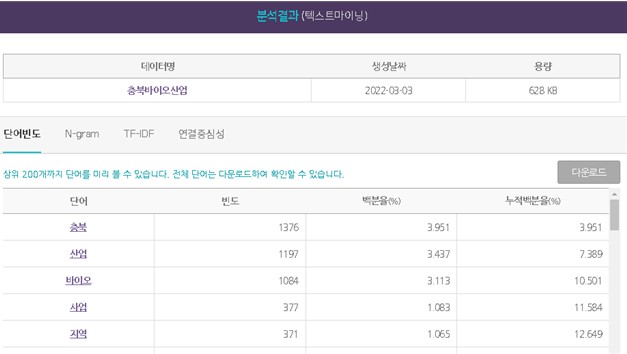
1) 텍스트 마이닝: 형태소 분석이 완료되면, 바로 편집하기/업로드를 통해 단어를 보거나 추가 정제할 수 있다. 웹 상에서 빠르고 쉽게 단어 편집을 하고자 할 경우에는 바로편집하기 기능을, 정제 데이터를 내려 받아 작업을 하고자 할 경우 업로드 기능을 사용한다. 원문 데이터 및 정제 데이터를 각각 엑셀이나 텍스트 포맷 형태로 다운로드한다. 데이터 편집 윈도우 창을 통하여 특정 키워드의 변경도 가능하다. 파일 업로드 기능은 원문 데이터가 아닌 정제 데이터를 다운로드하여 단어 편집을 진행 후 정제가 완료된 데이터를 업로드 한다. 이때 엑셀 파일 형식의 데이터를 txt 파일로 변경(UTF-8로 인코딩)하여 단어편집 후 업로드하며, ‘편집된 데이터가 적용되어 있습니다’라는 텍스트가 뜨면 파일 업로드 기능을 사용할 수 있다.
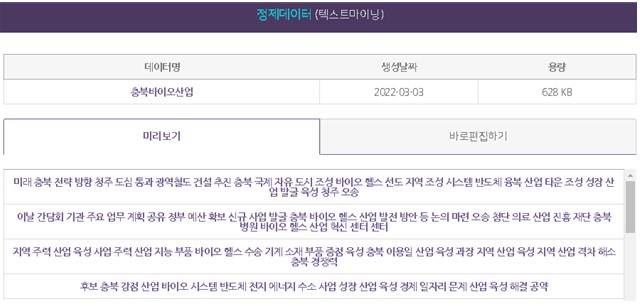
분석 결과는 단어 빈도, N-gram, TF-IDF, 연결 중심성, 개체명 인식 결과를 바로 실시간으로 분석하여 제공한다. 보여주기는 상위 200개 단어까지만 노출되며, 전체를 보기위해서는 별도로 다운로드를 할 수 있다.
2) 매트릭스: 바로선택하기/업로드를 통해 매트릭스로 생성한 단어를 선정할 수 있다. 1-모드 혹은 2-모드중에 선택이 가능하며, 이후 직접 매트릭스의 열과 행을 결정할 단어를 선택해주어여 한다. 선택한 단언간의 매트릭스 결과를 제시하면, 본 결과는 추후 추가 분석을 위하여 사용된다. 분석 결과는 유클리디언 계수, 코사인 계수, 자카드 계수, 상관계수 등으로 결과 값을 제공한다.
3) 담론 분석: 담론은 문서 내에서 동시에 등장(공출현)하는 단어 사이의 관계를 나타내는 분석으로, 상관관계를 이용하여 단어 간의 관계 패턴에 따라 군집화하는 분석 방법이다. CONCOR(CONvergence of iteration CORealtion)분석이라고 부르며, 문서 내에서 동시에 등장(공출현)하는 단어 사이의 관계를 군집화하는 방법으로, 단어 간 상관관계를 통해 분석 키워드에 얽힌 주제들을 쉽게 파악할 수 있어 시민들의 생각 즉, 여론에 대한 분석(오피니언마이닝) 등이 필요한 상황에서 유용하게 사용할 수 있다.
상관관계 분석을 반복적으로 수행하여 적정한 수준의 유사성 집단을 찾아내는 방법이다. 담론분석의 블록(block)은 구분된 구조적 등위성 집단을 말한다. 노드들의 집합에 해당하는 블록들을 파악하고, 이러한 블록 간의 관계도 파악이 가능한 분석 방식이다. 유사도 계산은 상관관계 계수를 이용하여 분석할 수 있다. 바로 전 단계에서 계산한 매트릭스를 사용하며, 담론 개수, 즉 군집화 개수는 2개, 4개, 8개, 16개 중 선택이 가능하다.
4) 감성 분석: 텍스톰의 감성분석은 크게 두가지 기능이 있다. 첫 번째, 문장의 내용을 긍정/중립/부정 으로 구분할 수 있는 감성 분류 분석이며, 두 번째, 원문데이터 안에 감성과 관련된 키워드가 몇 번 들어갔는지 알려주는 감성 단어 빈도 분석이 있다.
우선, 감성 분류 분석은 베이지안 분류기(Bayes Classifier)를 통해 기계학습 기법의 감성분석 기능을 제공한다. 연구자가 직접 학습데이터를 구성하여 적용함으로써 분석 주제의 제한 없이 모든 분야의 데이터에서 감성분석이 가능하다. 감성 분류 분석을 진행하기 위해서 가장 먼저 이뤄져야 하는 단계는 '학습데이터' 만들기이다. '학습데이터'란 전체 데이터를 분류하기 위한 기준이 되는 데이터로 '학습데이터'를 얼마나 정확하게 만드냐에 따라 분류의 질이 달라질 수 있다. 학습데이터는 최소 100건에서 최대 1,000건의 데이터로 만드는 것을 추천하고 있으며, 긍정/중립/부정의 비율이 비슷할 수록 정확한 결과를 얻을 수 있다.

학습데이터 만드는 방법은 분류를 진행하실 원문데이터 Excel 양식을 다운 받아, 우 100 ~ 1,000건(행) 정도 편집하여 업로드 해주면 된다. A열에는 본문, B열에는 해당 본문에 대한 극성(긍정/중립/부정)을 직접 넣어주면 된다 직접 만든 학습데이터를 업로드하고 적용이 되면 극성별로 분류된 결과를 얻으실 수 있다. 기본적인 분석은 끝났지만, 긍정/중립/부정별로 조금 더 심화된 분석을 진행하고 싶을 경우에는 추가분석 기능을 이용하여, 긍정/중립/부정의 데이터를 다시 한번 분석을 진행하실 수 있다. 추가분석을 진행하여 네트워크 그레프를 그리면, 긍정 문서 중 어떤 키워드가 많이 나왔는지, 긍정적인 영향을 주는 이유는 무엇인지 등 다양한 인사이트를 얻을 수 있다.
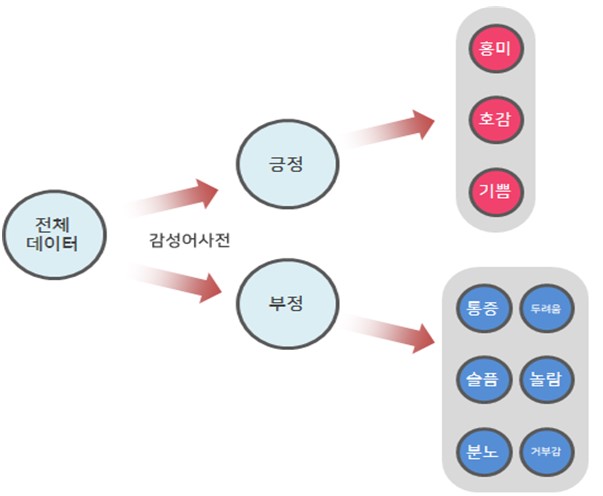
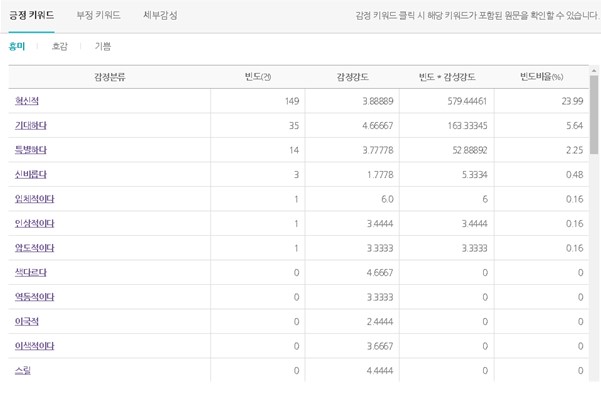
또 다른 감성 단어 빈도 분석은 원문데이터 중 감성과 관련된 단어를 찾아서 빈도를 보여주는 기능이다. 감성 단어는 텍스톰에서 자체 제작한 감성어 어휘 사전을 이용하여 단어를 분류한다. 텍스톰에서 자체 제작한 감성어 어휘사전은 긍정/ 부정이라는 카테고리 안에, 긍정의 키워드는 흥미/ 호감/ 기쁨 3개의 단어가, 부정의 키워드에는 통증/ 슬픔/ 분노/ 두려움/ 놀람/ 거부감 6개의 단어가 있다. 다시 기쁨이라는 단어안에는 기쁨을 표현하는 수 많은 단어를 강도에 따라 표준화(감성강도/7점 만점)를 시켜놨다. 예를 들어 호감이라는 단어 안에 "행복하다"와 "그저그렇다" 라는 단어가 있을 경우 "행복하다"라는 단어에는 5점, "그저그렇다"라는 단어에는 1점을 주어 같은 호감안에 들어가는 단어라도 감성 강도를 다르게 사전을 구축하였다.
감성 분류 분석을 진행을 위해 학습데이터를 업로드한 경우에는 감성단어 빈도 분석을 바로 확인하실 수 있다. 하지만 감성 분류 분석을 진행하지 않고, 감성단어 빈도 분석만 진행을 원하실 경우에는 엑셀 양식의 파일 업로드하면 결과를 확인할 수 있다. 감성단어 빈도는 키워드의 빈도뿐 아니라 감성 강도도 함께 보여주기 때문에, 다양한 인사이트를 찾을 수 있다. 예를 들어 '특별하다' 키워드의 경우 빈도는 261건으로, '기대하다' 키워드 234건 보다 높은 빈도를 보여주고 있다. 하지만 감성강도를 보면 '특별하다'는 3.77, '기대하다'는 4.66으로 흥미라는 단어에서는 '기대하다'가 더 높은 강도를 갖는다는 것을 알 수 있다. 빈도*감성정도를 보면 '특별하다'는 986, '기대하다'는 1092로 빈도수는 '기대하다'가 낮지만, 전체 문장에서 '흥미'라는 감정에 더 많은 영향을 주는 키워드는 '기대하다'라는 것을 알 수 있다. 뿐만 아니라 시각화 결과를 통해 전체 데이터 중 어떤 감성강도가 많이 차지했는지를 확인이 가능한 강도 감성분석과, 세부감성 중 어떤 감정이 비율이 높은지 확인이 가능한 세부감정 감성분석 시각화를 제공하고 있다.
5) 토픽 분석: 토픽 분석을 알기 전에 토픽모델의 개념을 알고 있어야 한다. 토픽모델(Topic Model)이란 문서 집합의 "주제"를 발견하기 위한 통계적 모델 중 하나로, 텍스트 본문의 숨겨진 의미구조를 발견하기 위해 사용되는 텍스트 마이닝 기법 중 하나이다. 특정 주제에 관한 문서에는 그 "주제"에 관한 단어가 다른 단어들에 비해 더 자주 등장한다. 예를 들어 '강아지'에 대한 문서에서는 '산책', '개밥' 단어가 더 자주 등장하는 반면, '고양이'에 대한 문서에서는 '야옹', '캣타워' 단어가 더 자주 등장한다. 이렇게 함께 자주 등장하는 단어들은 대게 유사한 의미를 지니게 되는데 이를 잠재적인 "주제"로 정의할 수 있다. 즉 '산책'과 '개밥'을 하나의 주제로 묶고, '야옹'과 '캣타워'를 또다른 주제로 묶는 모형을 만드는 것이 토픽 모델의 개략적인 개념이다. 텍스톰에서는 두 가지 종류의 토픽분석을 제공하고 있다.
첫째, 문서 내 단어들의 공출현 관계를 토대로 벡터화하여 인접 단어를 같은 그룹으로 묶어주는 Word-level Semantic Clustering이다. Word-level Semantic Clustering 분석을 진행하기 위해서는 군집 수(K값)와 군집 안에 들어갈 단어의 수를 선택해야한다. 텍스톰에서 기본 값은 군집 수 10개, 군집별 단어 수 20개를 제공하고 있다. 결과로 나올 군집 수가 사용자가 지정한 것 보다 작을 경우에는 임의로 지정된다.
둘째, 대량의 문서군으로부터 주제(토픽)을 자동으로 찾아내기 위한 알고리즘으로, 유사한 의미를 가진 단어들을 집단화하는 LDA Topic Modeling이다. LDA Topic Modeling을 진행하기 위해서는 토픽 수와 토픽에 들어갈 단어의 수를 결정해야 한다. 기본으로 제공하는 토픽의 수는 10개이며, 단어수는 20개다. 다음으로 랜덤 값을 선택해주시면 된다. LDA모델은 토픽수를 입력 받으면 전체 문서에 토픽을 랜덤으로 할당한 후, 토픽의 재할당을 반복 수행하여 문서와 단어의 토픽을 찾은 알고리즘이다 따라서, 토픽모델링은 무작위 토픽 할당이 이루어지는 것을 전제로 하고 있다. 다만, 이렇게 무작위 할당을 진행할 경우 초기 할당 값에 따라서 학습 대상이 되는 데이터가 달라지므로, 분석 결과의 재현성이 떨어지기 때문에 같은 데이터로 같은 분석을 진행했더라도 결과 값이 달라질 수 있다. 따라서 원칙적으로는 무작위 할당 옵션은 사용하는 것이 권장되나, 분석 결과의 재현성을 확보하고 싶은 경우에는 무작위 할당을 하지 않는 옵션을 사용하실 수 있다.
6) 시계열 분석: 수집단위에서 설정한 기간별로, 선택한 단어의 출현 빈도를 분석할 수 있다. 시계열분석은 수집하기에서 수집단위를 사용하여 수집한 데이터만 분석이 가능하다. 기간의 변동에 따른 데이터의 패턴을 확인할 수 있다.
2. 시각화 보기
분석한 결과는 다양한 시각화 결과물로 분류하여 볼 수 있다. 통계적 결과를 시각화를 통하겨 빠르고 직관적으로 이해할 수 있도록 도와준다. 제공되는 시각화 결과물은 워드클라우드, 바챠트, 에고네트워크, 네트웤, 개체명 인식, LDA, 클러스터링, 매트릭스 챠트, 담론 분석, 문서 감성 분석, 감성단어 분석, 감성단어 워드클라우드이다. 각각의 시각화 결과물은 그림 파일 포맷으로 다운로드하거나 크기, 색상, 포함 단어의 수 등을 화면 우측 창을 통하여 조절 가능하다.

'높이자! 비즈니스 생산성' 카테고리의 다른 글
| Textom으로하는 웹 스크래핑 Big data 분석 (3) (904) | 2022.05.01 |
|---|---|
| Textom으로하는 웹 스크래핑 Big data 분석 (2) (639) | 2022.05.01 |
| Textom으로하는 웹 스크래핑 Big data 분석 (1) (635) | 2022.05.01 |
| Google로 하는 마켓센싱(2 (623) | 2022.03.21 |
| Google로 하는 마켓센싱(1) (545) | 2022.03.21 |